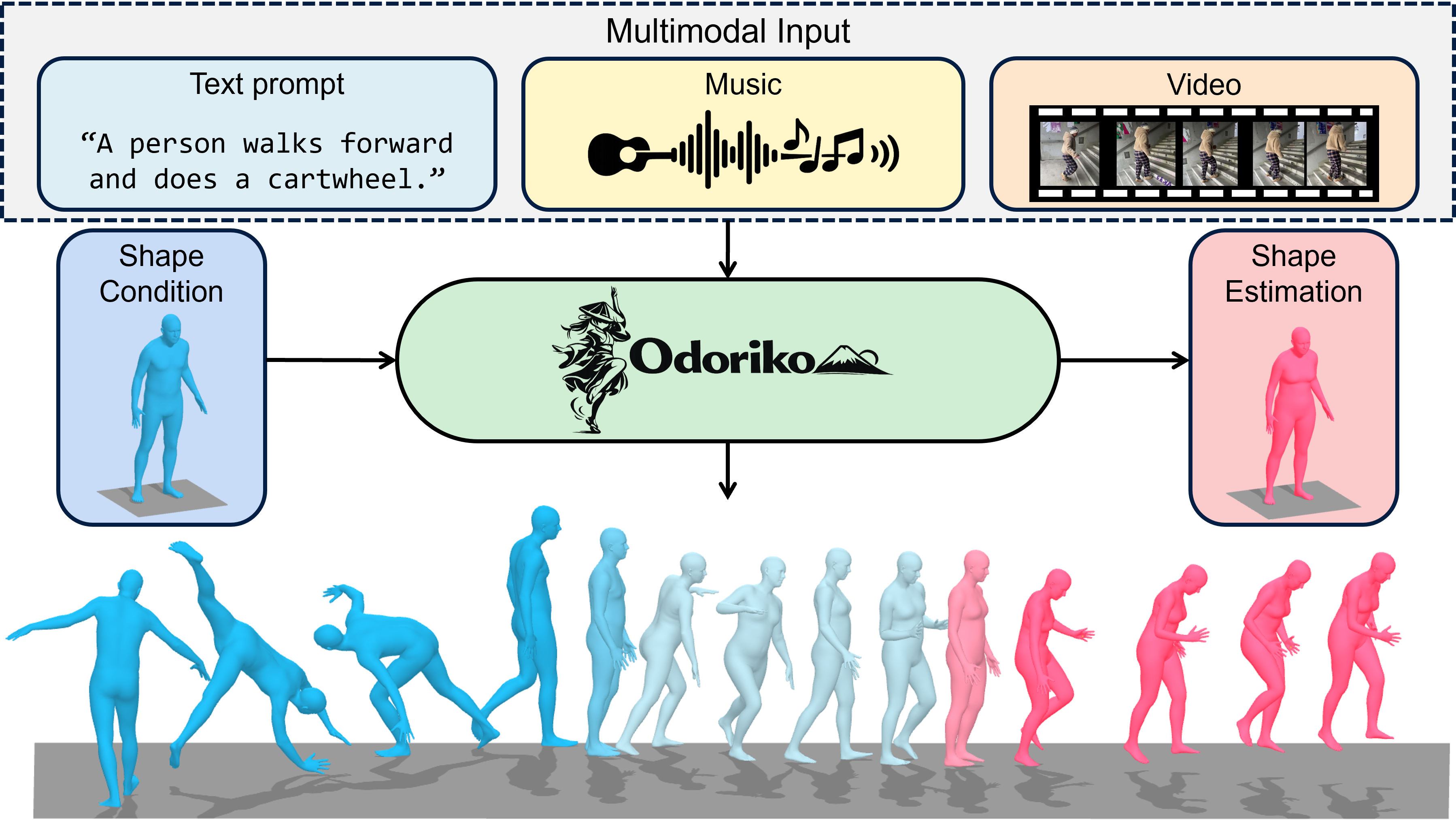
Human motion generation has been widely studied across diverse input modalities — text, music, and video — and recent efforts have unified these into single multimodal frameworks. However, while morphological factors such as gender and body shape are known to produce distinct kinematic signatures, no existing unified framework incorporates this into generation, treating all subjects as morphologically equivalent.
We present Odoriko, the first unified multimodal motion generation framework that reflects subject bio-morphological information directly in synthesized motion output. Rather than averaging over subject variation, Odoriko generates motion that is consistent with who is moving, not just what they are asked to do — across text, music, and video conditions within a single model. When explicit morphological information is unavailable, Odoriko additionally recovers subject morphology alongside motion, unifying estimation and generation in one framework.
Extensive experiments across text-to-motion, music-to-dance, and video-to-motion benchmarks demonstrate that Odoriko matches or exceeds prior specialized models on standard metrics, while enabling morphology-consistent generation that no existing unified framework supports.
We compare Odoriko with existing multimodal motion generation models, MotionCraft and GENMO.
"A person is doing a forward kick with each leg."
"Someone is walking in a backward motion."
"A person picks up a heavy object from the ground, places it on a table, and walks away."
"A person walks forward and does a cartwheel."
Mixed Genre Choreography
Classic ShenYun Dance
Street and Urban Dance
Hip-hop Dance
As our model focuses on local pose estimation, global motion is reconstructed using ground-truth translation. The subjects' shape and gender are directly predicted by Odoriko.
Odoriko generates motions that faithfully follow the input shape conditioning. Even with identical text or music inputs, the resulting motions vary according to the subjects' shape, producing biomorphologically plausible and consistent movements. During inference, we fix the random seed so that differences arise only from the shape conditioning.
"A person stretches both arms overhead and reaches as high as possible."
"A person repeatedly performs explosive vertical jumps, trying to reach maximum height."
"A person carefully walks heel-to-toe across a very narrow beam while extending their arms for balance."
@inproceedings{shim2026odoriko,
title = {Odoriko: A Shape-Aware Multimodal Diffusion Framework for Human Motion},
author = {Shim, Dongseok and Tanke, Julian and Uchida, Kengo and Simon, Christian
and Saito, Koichi and Shibuya, Takashi and Takahashi, Shusuke and Mitsufuji, Yuki},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026}
}